블록체인 게임에서 채굴을 하는 것이 합법인가요?
2021년 9월, 국가발전개혁위원회(NDRC)와 다른 부처가 공동으로 가상 화폐 "채굴" 활동 정리에 관한 통지(이하 "통지")를 발표하여 국가가 채굴을 금지했습니다.
 JinseFinance
JinseFinance

저자: Arweave Oasis
지난 5년 동안 Arweave의 반복적인 여정에 대해 다룬 이전 글 Arweave의 합의 메커니즘의 반복에서 버전 2.6의 보다 포괄적인 반복을 약속드린 바 있으며, 오늘 이 글을 다시 읽어보시죠. Arweave의 반복적 합의 메커니즘에서 Arweave 버전 2.6에 대한 보다 포괄적인 분석을 제공하겠다고 약속드린 바 있으며, 그 약속을 지키기 위해 이 자리를 마련했습니다. 이 글에서는 그 약속을 지키기 위해 버전 2.6의 합의 메커니즘 설계에 대해 자세히 살펴보겠습니다.
비트코인의 다음 반감기가 시작되기까지 약 한 달이 남았습니다. 하지만 저자는 사토시 나카모토의 비전, 즉 모든 사람이 CPU로 참여할 수 있는 합의는 실현되지 않았다고 생각합니다. 하지만, Arweave의 반복적인 메커니즘은 사토시 나카모토의 원래 비전에 더 충실했을 수 있으며, 버전 2.6은 Arweave 네트워크가 사토시 나카모토의 기대에 진정으로 부합하기 시작할 수 있게 해줍니다. 이전 버전보다 크게 개선된 점은 다음과 같습니다.
시스템의 합의 유지에 범용 등급의 CPU + 기계식 하드 드라이브가 관여할 수 있도록 하드웨어 가속을 제한하여 스토리지 비용을 줄이고,
합의 비용을 가능한 한 에너지 집약적인 해싱 군비 경쟁이 아닌 효율적인 데이터 스토리지로
채굴자들이 전체 Arweave 데이터 세트의 자체 복사본을 구축하도록 장려하여 더 빠른 데이터 라우팅과 더 분산된 저장을 가능하게 합니다.
위의 목표에 따라 2.6 버전의 메커니즘은 대략 다음과 같습니다:
원래의 SPoRA 메커니즘에 해시라는 새로운 구성 요소가 추가되었습니다. 체인이라는 새로운 구성 요소가 추가되었는데, 이는 앞서 언급한 암호화 알고리즘 시계로 매초마다 SHA-256 채굴 해시를 생성합니다.
채굴자는 저장된 데이터 파티션에서 파티션의 인덱스를 선택하고 마이닝 해시 및 마이닝 주소와 함께 이를 마이닝 입력으로 사용하여 마이닝을 시작합니다.
채굴자가 선택한 파티션에 백트래킹 범위 1을 생성하고, 위브 네트워크의 임의 위치에 백트래킹 범위 2를 생성합니다.
백트래킹 범위 1의 백트래킹 청크(청크)를 차례로 사용하여 계산하여 블록 솔루션인지 여부를 확인합니다. 계산 결과가 현재 네트워크 난이도보다 크면 채굴자에게 블록을 종료할 수 있는 권한이 부여되고, 실패하면 역추적 범위의 다음 역추적 블록이 계산됩니다.
2 범위의 역추적 블록도 계산을 통해 유효성을 검사할 수 있지만, 이 경우 1 범위의 해시가 필요합니다.
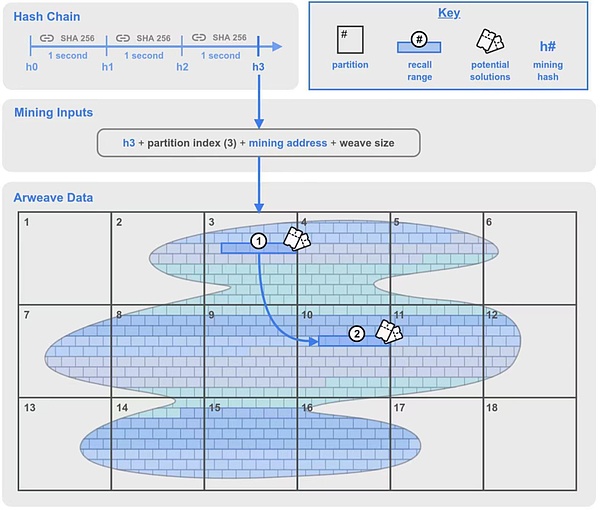
그림. 1: 2.6 버전의 합의 메커니즘 도식
이 메커니즘에서 사용되는 다양한 용어와 개념에 대해 알아봅시다.
데이터 짜기:
청크: 각 청크의 크기는 일반적으로 256KB이며, 청크를 얻으려면 채굴자는 해당 청크를 패킹 및 해시하고 SPoRA 채굴 과정에서 데이터의 사본을 저장했음을 증명해야 합니다.
파티션: "파티션"은 버전 2.6의 새로운 개념입니다. 3.6TB마다 파티션이 있습니다. 파티션은 네트워크의 시작(인덱스 0)부터 전체 네트워크를 포괄하는 파티션 수까지 번호가 매겨집니다.
리콜 범위: 리콜 범위도 버전 2.6의 새로운 개념입니다. 이는 특정 오프셋에서 시작하여 직조된 네트워크에서 연속적인 100MB 청크의 연속입니다. 청크당 256KB로 백홀 범위에는 400개의 청크가 있습니다. 이 메커니즘에는 아래에서 자세히 설명하는 것처럼 두 개의 역방향 범위가 있습니다.
잠재적 해결책: 백트래킹 범위의 각 256KB 블록은 블록에서 벗어날 수 있는 잠재적 해결책이 될 것입니다. 채굴 과정의 일부로 각 블록은 네트워크의 난이도 요건을 충족하는지 테스트하기 위해 해시됩니다. 이를 충족하면 채굴자는 블록에서 나갈 수 있는 권리를 얻고 채굴에 대한 보상을 받게 됩니다. 그렇지 않은 경우, 채굴자는 계속해서 범위 내의 다음 256KB 블록으로 역추적을 시도합니다.
해시 체인: 해시 체인은 버전 2.6의 주요 업데이트로, 최대 해시량을 제한하는 속도 제한기 역할을 하는 암호화 시계가 이전 SPoRA에 추가되었습니다. 해시 체인은 SHA-256 함수를 사용하여 데이터 조각을 연속적으로 해시하는 방식으로 생성됩니다. 이 프로세스는 병렬로 수행할 수 없으며(일반 소비자용 CPU는 쉽게 수행할 수 있음), 해시 체인은 일정 횟수의 연속 해시를 수행하여 1초의 지연을 달성합니다.
채굴 해시: 충분한 수의 연속 해시 후(즉, 1초 지연 후) 해시 체인은 채굴에 유효한 것으로 간주되는 해시값을 생성합니다. 채굴 해시는 모든 채굴자 사이에서 일관되며 모든 채굴자가 확인할 수 있다는 점에 유의해야 합니다.
이제 필요한 모든 명명법 개념을 소개한 후, 버전 2.6이 어떻게 작동하는지 더 잘 이해할 수 있도록 함께 모여 최선의 전략을 세우도록 하겠습니다.
이전에도 여러 번 다루었던 Arweave의 전반적인 목표는 네트워크에 저장된 데이터의 사본 수를 최대화하는 것입니다. 하지만 무엇을 저장할까요? 그리고 어떻게 저장할까요? 여기에는 몇 가지 요구 사항과 문이 있습니다. 여기에서는 최적의 전략을 채택하는 방법에 대해 설명합니다.
복제본과 사본
2.6 버전부터 다양한 기술 자료에서 복제본과 사본이라는 용어를 자주 보았습니다. 이 때문에 메커니즘을 이해하는 데 큰 장애물이 되었습니다. 이해를 돕기 위해 저는 복제본을 '사본'으로, 사본을 '백업'으로 번역하는 편입니다.
사본은 동일한 데이터의 백업 간에 차이가 없는 단순한 데이터의 복사본입니다.
복제본은 고유성을 위해 데이터를 한 번 처리한 후 고유성을 위해 저장하는 행위로, Arweave 네트워크는 단순한 백업 저장이 아닌 복제본의 저장을 권장합니다.
주: 버전 2.7에서 합의 메커니즘은 간결한 복제 증명인 SPoRes가 되었으며, 앞으로 설명할 복제본 스토리지의 핵심은 바로 이것입니다.
고유 복제본 패키징
고유 복제본은 아위브 메커니즘에서 매우 중요하며, 마이너가 블록에서 블록을 얻기 위해서는 모든 데이터를 특정 포맷으로 패키징하여 자신만의 고유 복제본을 만드는 것이 전제 조건입니다.
새 노드를 운영하려면 다른 채굴자가 이미 패키징한 데이터를 그냥 복사할 수 없습니다. 먼저 Arweave 위브 네트워크에서 원시 데이터를 다운로드하고 동기화한 다음(물론 모든 데이터를 다운로드할 필요는 없지만 일부만 다운로드해도 괜찮으며, 자체 데이터 정책을 설정하여 위험한 데이터를 필터링할 수 있습니다), RandomX 기능을 사용하여 해당 원시 데이터의 각 청크를 패키징하여 잠재적인 채굴 솔루션으로 만들어야 합니다.
패킹 프로세스는 RandomX 함수에 패킹 키를 제공하고, 이 함수가 여러 연산을 실행하여 원시 데이터 청크를 패킹하는 데 사용되는 결과를 생성하도록 하는 것으로 구성됩니다. 패킹된 데이터 블록을 언패킹하는 과정도 동일하며, 패킹 키를 제공하고 여러 연산의 결과를 사용하여 패킹된 데이터 블록의 패킹을 해제합니다.
버전 2.5에서 패킹 키 백업은 chunk_offset(청크의 오프셋, 청크의 위치 매개변수로도 해석할 수 있음) 및 tx_root(트랜잭션 루트)와 연결된 SHA256 해시입니다. 이렇게 하면 각 마이닝 솔루션이 특정 블록에 있는 데이터 블록의 고유한 사본에서 나오도록 보장할 수 있습니다. 데이터 블록의 여러 백업이 파괴 네트워크의 서로 다른 위치에 존재하는 경우, 각 백업은 고유한 사본으로 개별적으로 백업해야 합니다.
버전 2.6에서는 이 백업 키가 chunk_offset, tx_root, miner_address의 연결에 대한 SHA256 해시로 확장되었습니다. 이는 각 사본이 각 채굴자 주소에 고유하다는 것을 의미합니다.
전체 사본 저장의 장점
이 알고리즘은 채굴자가 여러 번 복제된 부분 사본이 아닌 고유한 전체 사본을 생성하도록 제안하며, 이는 네트워크 전체에 데이터를 균등하게 분배할 수 있도록 합니다.
이 부분을 어떻게 이해해야 할까요? 아래 두 다이어그램을 비교하여 이해해 보겠습니다.
먼저 전체 Arweave 프랙처 네트워크가 총 16개의 데이터 파티션을 생성한다고 가정해 봅시다.
첫 번째 시나리오:
채굴자 밥은 데이터를 다운로드하는 데 시간이 너무 많이 걸린다고 생각하여 파손된 네트워크의 처음 4개 파티션의 데이터만 다운로드했습니다.
이 4개 파티션의 채굴 복사본을 최대화하기 위해 밥은 이 4개 파티션에서 데이터 복사본을 4개 만들고 각각 다른 4개의 채굴 주소를 가진 4개의 고유 복사본 리소스로 구성하여 자신의 저장소를 4개로 채우는 기발한 아이디어를 냈고, 이제 밥의 저장소에는 16개의 파티션이 생겼습니다. 이는 문제가 없으며 고유 복사본에 대한 규칙을 준수합니다.
다음으로, Bob은 매초마다 마이닝 해시를 얻을 때 각 파티션에 대해 역방향 범위의 자료를 생성할 수 있으며, 여기서 데이터 블록의 위반 여부를 테스트합니다. 이렇게 하면 Bob은 1초에 400* 16=6400개의 잠재적인 마이닝 솔루션을 얻을 수 있습니다.
그러나 밥은 자신의 작은 독창성에 대한 두 번째 대가를 치렀는데, 바로 채굴 기회 범위를 잃어야 했기 때문입니다. 여기 '작은 물음표'가 보이시나요? 이는 밥이 저장하지 않은 데이터의 파티션을 표시하는 것으로, 문제의 두 번째 역방향 범위가 밥의 하드 드라이브에서 발견되지 않았다는 사실을 나타냅니다. 물론 운이 좋게도 Bob이 저장한 4개의 파티션을 상징하는 아래쪽 불빛도 있는데, 이는 25%에 불과한 1600개의 잠재적 솔루션입니다.
따라서 이 전략은 Bob에게 초당 6400+1600=8000개의 잠재적 솔루션을 제공합니다.
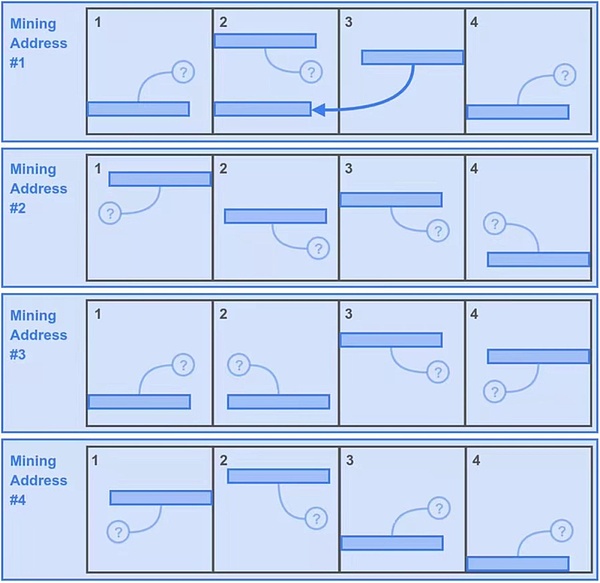
그림 2: 첫 번째 시나리오, 밥의 '영리한' 전략
두 번째 시나리오:
이제 두 번째 시나리오를 살펴보겠습니다. 두 개의 역방향 범위에 대한 메커니즘의 배열로 인해 문제가 있는 배수의 고유 복사본을 저장하는 것이 더 나은 전략입니다. 이는 그림 3에 나와 있습니다.
채굴자 앨리스는 밥만큼 '똑똑하고 영리하지' 않기 때문에 본능적으로 16개의 파티션 데이터를 모두 다운로드하고 단 하나의 채굴 주소로 16개의 백업에 대한 고유한 사본을 만듭니다.
앨리스도 16개의 파티션을 사용하기 때문에 첫 번째 역추적 범위의 잠재적 솔루션의 총 개수는 밥의 개수인 6400개와 일치합니다.
그러나 이 경우 앨리스는 두 번째 역방향 범위의 모든 잠재적 솔루션을 얻습니다. 이는 추가로 6400입니다.
따라서 앨리스 전략은 초당 6400+6400=12800개의 잠재적 솔루션을 얻게 됩니다. 장점은 자명합니다.
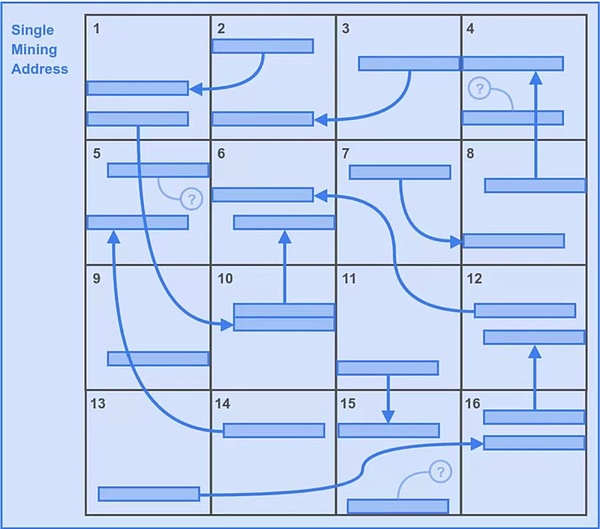
그림 3: 앨리스의 전략, 분명 유리한 점
백트래킹 범위의 역할
채굴자가 2.5까지 저장 증명을 찾아서 제공할 수 있는 함수에서 개별 백트래킹 블록의 오프셋을 무작위로 해시하는 것이 왜 그렇게 중요한지 궁금할 수도 있습니다. 증명을 찾아 저장하는 데 2.6에서는 왜 다양한 역추적 범위를 해시화할까요?
이유는 이해하기 쉽습니다. 역추적 범위는 연속적인 데이터 블록으로 구성되며, 이는 기계식 하드디스크(HDD)의 읽기 헤드의 움직임을 최소화하는 방식으로 구조화되어 있습니다. 이러한 접근 방식에 의한 물리적 최적화를 통해 HDD의 읽기 성능을 더 비싼 SSD(하드 드라이브)와 나란히 배치할 수 있습니다. 이는 마치 한 손과 한 발을 SSD에 묶는 것과 같으며, 물론 초당 4개의 역방향 범위를 전송할 수 있는 고가의 SSD가 여전히 약간의 속도 이점을 가지고 있습니다. 하지만 더 저렴한 HDD에 비해 얼마나 많은 횟수를 전송할 수 있는지가 채굴자들의 선택을 좌우하는 핵심 지표가 될 것입니다.
이제 다음 새로운 블록의 검증에 대해 알아보겠습니다.
새 블록을 승인하려면 검증자는 블록 생성자가 동기화한 새 블록을 검증해야 하며, 이를 위해 자체적으로 생성한 마이닝 해시로 새 블록의 마이닝 해시를 검증할 수 있어야 합니다.
검증자가 현재 해시 체인의 헤드에 있지 않은 경우, 각 채굴 해시는 25개의 40밀리초 체크포인트로 구성됩니다. 이러한 체크포인트는 연속적인 40밀리초 해시의 결과이며, 이전 마이닝 해시의 시작부터 1초 간격을 나타냅니다.
검증자는 새로 받은 블록을 다른 노드로 전파하기 전에 40밀리초 안에 처음 25개의 체크포인트 검증을 빠르게 완료하고, 검증에 성공하면 블록의 전파를 트리거하고 나머지 체크포인트의 검증을 완료하기 위해 진행합니다. 완전한 체크포인트는 나머지 모든 체크포인트를 검증함으로써 이루어집니다. 처음 25개의 체크포인트에 이어 500개의 체크포인트가 검증되고, 이후 500개의 체크포인트가 검증되면 각 그룹에 대해 이후 500개의 체크포인트 간 간격이 두 배로 늘어납니다.
채굴 해시를 생성할 때 해시 체인은 한 줄로 순차적으로 이어져야 합니다. 그러나 체크포인트를 검증하는 검증자가 해시 검증을 수행할 수 있으므로 블록 검증을 훨씬 더 짧고 효율적으로 수행할 수 있습니다.
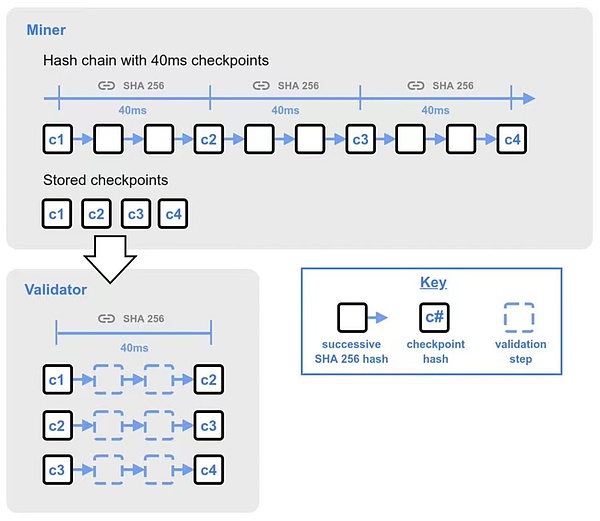
그림 4: 해시 체인 검증 프로세스
해시 체인 시딩
채굴자 또는 풀의 SHA256 해시 연산 능력이 더 빠르다면, 해당 해시 체인이 네트워크의 다른 노드보다 앞서 있을 수 있습니다. 시간이 지남에 따라 이러한 블록 속도 우위는 거대한 해시 체인 오프셋으로 누적되어 나머지 검증자와 동기화되지 않는 채굴 해시를 생성할 수 있습니다. 이는 통제할 수 없는 일련의 포크와 재구성으로 이어질 수 있습니다.
아르위브는 이러한 해시 체인 오프셋의 가능성을 줄이기 위해 일정 간격으로 과거 블록의 토큰을 사용하여 글로벌 해시 체인을 동기화합니다. 이렇게 하면 주기적으로 해시 체인에 새로운 해시 체인을 시드하여 개별 마이너의 해시 체인을 검증된 블록과 동기화합니다.
해시 체인은 50 * 120 마이닝 해시마다 새로운 시드 블록이 선택되는 간격으로 시드됩니다(50은 블록 수, 120은 블록 생성 주기 2분 이내의 마이닝 해시 수). 따라서 시드 블록은 약 50개의 아위브 블록마다 한 번씩 나타나지만, 블록 생성 주기의 변동성으로 인해 시드 블록이 50개 블록보다 조금 일찍 나타날 수도 있습니다.
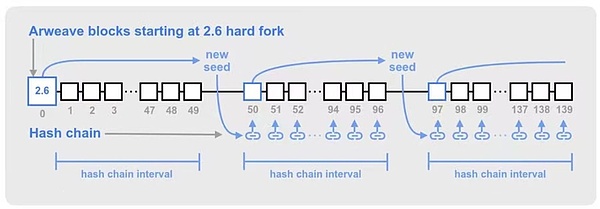
그림 5: 해시 체인 시드가 생성되는 방식
위 내용은 저자들이 시간을 들여 작성한 2.6 사양에서 발췌한 것으로, 이를 통해 Arweave가 2.6부터 전체 네트워크를 운영하기 위해 저전력, 그 아래로는 보다 탈중앙화된 이념적 메커니즘을 구현하고 있다는 것을 알 수 있습니다. 사토시 나카모토의 비전은 아위브에서 실현되고 있습니다.
Arweave 2.6:
https://2-6-spec.arweave.dev/https://2-6-spec.arweave.dev
2021년 9월, 국가발전개혁위원회(NDRC)와 다른 부처가 공동으로 가상 화폐 "채굴" 활동 정리에 관한 통지(이하 "통지")를 발표하여 국가가 채굴을 금지했습니다.
JinseFinance공식 발표에 따르면, 로닌 네트워크 기반의 소셜 네트워크 게임인 46번째 프로젝트 픽셀(PIXEL)에서 코인의 새로운 코인 채굴이 시작되었습니다.
JinseFinance2023년은 비트코인 채굴자들에게는 분명 구원의 해입니다.
JinseFinance중국의 웹 2.0 시대는 하드웨어와 소프트웨어이든 O2O이든 세계 최고의 인터넷 인프라를 축적했으며, 인터넷 산업 업스트림 및 다운 스트림 산업 체인이 매우 완벽하며, 웹 2.0 배당 시대는 중국 정부가 분명히 단맛을 맛 보았습니다!
JinseFinance이 글에서는 2023년 Arweave 에코시스템 프로젝트의 주요 활동을 살펴봅니다.
JinseFinanceJinseFinance中国福州市委书记提供矿工津贴、保障电力长达4年,当庭认罪非法挖矿。
 fx168news
fx168newsBitcoin 광부의 생존의 열쇠는 수익과 운영 현금 흐름 간의 미묘한 균형입니다.
 Cointelegraph
CointelegraphChangjiang Daily 기자의 조사에 따르면 개인 "채굴"은 불법으로 의심되며 함정에 빠지기 쉽습니다.
 Ftftx
FtftxMicroStrategy 설립자 겸 CEO인 Michael Saylor는 “이번 분기에 우리는 비트코인 채굴의 에너지 효율성과 지속 가능성이 크게 개선되었으며 이러한 추세는 계속될 것”이라고 말했습니다.
Cointelegraph